Method 1: rpartition
Again, I'm going to post the recipe up here, and go into depth below. If you want the last <n> words in any sentence, you can do a transform with:
rpartition(value, /(\s\S+){<n>}$/)[1]
Be sure that all your data is more than <n> words. If you have sentences that are exactly n words, you'll get a null. You can either custom facet out that data with a :
length(value.split(" ")) ><n>
(what the length GREL does is described in this post.)
or use an if function:
if (length(value.split(" ")) ><n>, rpartition(value, /(\s\S+){<n>}$/)[1], value)
Method 2: Array arithmetic with split
Since you can access any element in split() by using the expression split()[<index>], you can use length(value.split(" ")) to calculate the indexes you need.
To get the last <n> words in any sentence, do a transform with:
value.split(" ")[length(value.split(" "))-<n>] + " " +
value.split(" ")[length(value.split(" "))-<n-1>] + " " +
value.split(" ")[length(value.split(" "))-<n-2>] + " " +
value.split(" ")[length(value.split(" "))-<n-3>] +
etc. until <n-whatever> = 1
ex. If I want the last 4 words in any sentence, my transform GREL would be:
value.split(" ")[length(value.split(" "))-4] + " " +
value.split(" ")[length(value.split(" "))-3] + " " +
value.split(" ")[length(value.split(" "))-2] + " " +
value.split(" ")[length(value.split(" "))-1]
Again, you will get unexpected results if your sentence is less than n words because negative indexes will wrap around. Either facet the short sentences away or use an if function:
if (length(value.split(" ")) ><n>, value.split(" ")[length(value.split(" "))-<n>] + " " + value.split(" ")[length(value.split(" "))-<n-1>] + " " + value.split(" ")[length(value.split(" "))-<n-2>] + " " + value.split(" ")[length(value.split(" "))-<n-3>] + <etc.>, value)
Detailed explanation - Method 1
If you are unfamiliar with arrays and/or how to access arrays in Open Refine, read this post first.
The function rpartition(value, /<your regex here>/) produces an array with:
["Everything in the string that comes before your regex", "the part of the string your regex matches", "everything in the string that comes after your regex"]
So, say if I have this info:
Dave "Count" Littlefield, Grace Cosenza, James Henniger at the Boardwalk (approximately 1943)
And I want to extract just the year, I would do rpartition(value, /[0-9]+/)
This generates array:
[ "Dave \"Count\" Littlefield, Grace Cosenza, James Henniger at the Boardwalk (approximately ", "1943", ")" ]
The regex is in element one, so all I have to do to output the year to the spreadsheet is to do a transform and type in: rpartition(value, /[0-9]+/)[1]
How does this relate to extracting the last n words in a sentence?
Simple - if I can figure out a regex to match the last n words in a sentence, I can put the regex in rpartition, and whatever is in array element 1 will be those words.
How does this relate to extracting the last n words in a sentence?
Simple - if I can figure out a regex to match the last n words in a sentence, I can put the regex in rpartition, and whatever is in array element 1 will be those words.
So, since I wanted only the last four words in any sentence, I tried rpartition(value, /(\s.*){4}$/)[1], and I got almost all of the sentence.
In order to debug, I removed the array index, just to make sure that the contents of the array were sound, and that the error was not me choosing the wrong index. Sure enough, the problem was with my regex. I ran afoul of greedy matching.
In order to debug, I removed the array index, just to make sure that the contents of the array were sound, and that the error was not me choosing the wrong index. Sure enough, the problem was with my regex. I ran afoul of greedy matching.
I went into a regex debugger (I highly recommend Regex Storm, which you can find with Google) and played with the expression until I figured out the regex I needed, which was (\s\S+){4}$
Then I dropped that back into rpartition like so:


And after checking to make sure that the last four words are correctly in element 1, I output the contents:

However, rpartition returns a null if the sentence is exactly four words, because the function only works if there are words before your regex.
To get around that, you can either custom facet out the 4 word sentences by splitting on the spaces, calculating the number of words with length (because 1 word = 1 array element), and then making sure it's more than 4 :

However, if you've already done the above to facet, you may as well use a transform with an if function, because you've just written a valid test condition.
To do the if, you can first start out with pseudocode:
if(<test condition that generates true/false values>,
true = <do something if true>,
false = <do something if false>)
Now, drop in your test condition:
false = <do something if false>)
To do the if, you can first start out with pseudocode:
if(<test condition that generates true/false values>,
true = <do something if true>,
false = <do something if false>)
Now, drop in your test condition:
if (<calculation to make sure there's more than 4 words>,
true = <do something if true>,false = <do something if false>)
Then figure out what you want to do:
if (<calculation to make sure there's more than 4 words>,
true = <rpartition string>,
false = <do nothing>)
"Do nothing" is always just using the statement, value:
if (<calculation to make sure there's more than 4 words>,
true = <rpartition string>,
value)
We've already done the rpartition, so drop it in there:
if (<calculation to make sure there's more than 4 words>,
rpartition (value,/ (\s\S+){4}$/)[1],
value)
And now, just drop in your test condition:
if (length(value.split(" ")) >4,
rpartition (value,/ (\s\S+){4}$/)[1],
value)
And now, you can perform the transformation:

We've already done the rpartition, so drop it in there:
if (<calculation to make sure there's more than 4 words>,
rpartition (value,/ (\s\S+){4}$/)[1],
value)
And now, just drop in your test condition:
if (length(value.split(" ")) >4,
rpartition (value,/ (\s\S+){4}$/)[1],
value)
And now, you can perform the transformation:

Detailed explanation - Method 2
The first thing to do whenever you want to split up a sentence into words is to split on the space (I'm assuming that there's no whitespace before any punctuation.)
As you can see, a value.split puts each word in each sentence into an array:

Elements 0-11 are now filled for the first row. As you know, you can output any element with value.split(" ")[<index number>]
However, <index number> doesn't have to be 0, 1, 2, 3, etc. typed out. A function that generates a number will work.
See what happens when length() is performed on the array:

Since it outputs a number, let's see what happens when I try to drop it into <index number>:
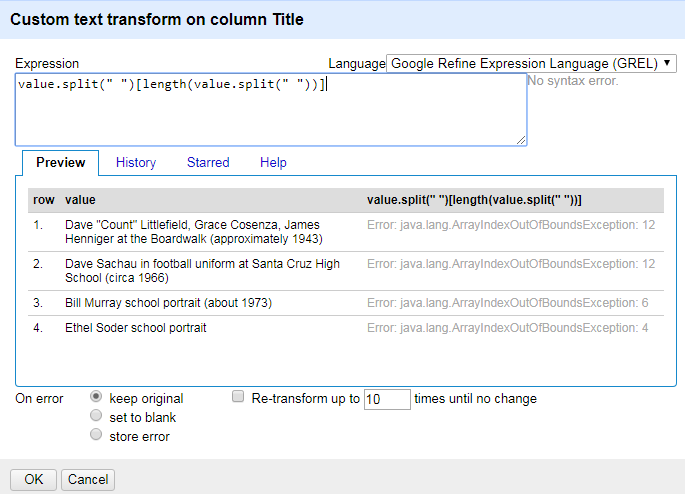
As you can see, I received an error. That's because length(value.split(" ")) counted out the total number of elements in the array. However, that number is one more than the maximum index number (because the index number starts at 0). The question is, how to get around this?
The answer is actually fairly simple, because you can also put in an arithmetic calculation for the index number. So you could write:
value.split(" ")[0]
value.split(" ")[0-0]
value.split(" ")[2-2]
value.split(" ")[3-3]
And they would all output the contents of the first element to the spreadsheet. Both parts of the calculation also don't have to be pre-typed numbers. You could also drop in any function that outputs a number.
So, since the problem is that the length function exceeds the maximum index number by one, look at what happens if I subtract 1 from it and use that as my index number:

I am now outputting the last word in the sentence. So, if I wanted the last two words, I would do the following:

So, basically, when you want the last n words in a sentence, start your expression by outputting
value.split(" ")[length(value.split(" "))-1] , then work backwards until your index is
length(value.split(" ") -n
No comments:
Post a Comment