I realized that I incorrectly listed how to do "do x if test condition is true, otherwise, do nothing" on my if statement cheatsheet. I corrected it, plus I added an entry on how to do a Marcedit Find/replace.
http://liwong.blogspot.com/2017/07/if-structure-cheat-sheet.html
Thursday, August 24, 2017
Anatomy of an if function
An if function is pretty simple - you write a test condition that will produce a true or false value when evaluated. If true, it will execute one set of functions that you designate, if false, another.
Or, in pseudocode:
if (<test condition>,
<execute these functions if true>,
<execute these functions if false>)
An if function is great if you want to only edit certain cells in a column, but not others. The hardest part, though, is writing the test condition. Basically, all you're really doing is trying to stack functions together to make GREL spit out a boolean. Here are a few hints to help write the test conditions.
Or, in pseudocode:
if (<test condition>,
<execute these functions if true>,
<execute these functions if false>)
An if function is great if you want to only edit certain cells in a column, but not others. The hardest part, though, is writing the test condition. Basically, all you're really doing is trying to stack functions together to make GREL spit out a boolean. Here are a few hints to help write the test conditions.
Wednesday, August 23, 2017
Troubleshooting problems with numerical strings
I figured out how to concatenate them together, but then I was getting strange results.
Official Open Refine release
Previous versions of Open Refine were beta and use at your own risk. The official release, Open Refine 2.7, is here.
Updated my Marcedit import post
I noticed a couple of more oddities with importing Marcedit files into Open Refine. Among other things, older versions import the 005 and 008 as numbers and not strings. (Numbers in Open Refine are green. Which I didn't know before.)
I've updated my original post.
I've updated my original post.
Friday, August 18, 2017
Recipe and walkthrough: counting up repeats of a word in a sentence
How do you count up the occurrences of <word> in a sentence? (or, in this case, find how many times "Nintendo" is in a 538?
sum(forEach(value.split(" "), temp, if(temp.contains("Nintendo"), 1, 0)))
Explanation:
Thursday, August 17, 2017
Walkthrough of extracting metadata from Fedora 3 and reconciling with Open Refine
Ruth Tillman wrote an extensive article on updating Fedora 3 metadata and using Open Refine to reconcile: http://journal.code4lib.org/articles/11179
Walkthrough of the Geonames Recon Service
Christina Harlow has a thorough post on configuring the Geonames Recon Service: http://christinaharlow.com/walkthrough-of-geonames-recon-service
Recipe: Text filtering with regular expressions
An alternative to writing a custom facet, especially if you want to filter based on a single word, is to use Open Refine's text filtering. It has regex capability, which is extremely useful.
For example, I have a file of videogame MARC records. The platforms under system requirements vary in verbiage and spelling. If I wanted to isolate out two platforms, such as all Xbox, Playstation, and Nintendo games, I could just use the text filtering function to find them instead of building a custom facet.
Caveats with the text filtering function - if you have a large file, it may hang. My file unfortunately came out to be about 69,000 rows, which Open Refine didn't like at all when I tried a text filter. I stopped the hanging by switching the view to 10 rows at a time and faceting on the 538 first.
So, to activate the text filter, all I have to do is pull down the menu on the Contents column and select "Text Filter"

A box will pop up in the left hand pane. All I have to do is enter my regular expression for finding all the Xbox and Playstation games: (.*[Nn]intendo.*|.*[Xx]box.*|.*[Pp]laystation.*), check the "regular expressions" box underneath where I entered my regex, and I'm good to go:
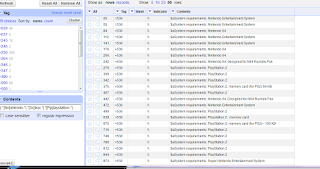
For example, I have a file of videogame MARC records. The platforms under system requirements vary in verbiage and spelling. If I wanted to isolate out two platforms, such as all Xbox, Playstation, and Nintendo games, I could just use the text filtering function to find them instead of building a custom facet.
Caveats with the text filtering function - if you have a large file, it may hang. My file unfortunately came out to be about 69,000 rows, which Open Refine didn't like at all when I tried a text filter. I stopped the hanging by switching the view to 10 rows at a time and faceting on the 538 first.
So, to activate the text filter, all I have to do is pull down the menu on the Contents column and select "Text Filter"

A box will pop up in the left hand pane. All I have to do is enter my regular expression for finding all the Xbox and Playstation games: (.*[Nn]intendo.*|.*[Xx]box.*|.*[Pp]laystation.*), check the "regular expressions" box underneath where I entered my regex, and I'm good to go:

Wednesday, August 16, 2017
Using Open Refine to control vocabularies from CONTENTdm
Here's a post from Elliot William about how he extracted metadata from CONTENTdm and used Open Refine to control the vocabulary: http://www.elliotdwilliams.com/controlling-all-the-names/
Thursday, August 10, 2017
Create custom facet names by using an if function
I covered custom faceting using booleans in this post. The other nice feature with custom facets is that if you don't want the labels "true" and "false" for your facet, you can just drop your boolean into an if function, and you can name your own facets.
In the custom facet I created using booleans, I used this piece of GREL to facet out any 856 |3 data that started with a volume label and didn't have a semi-colon:
and(value.startsWith("v"), not(value.contains(";")))
In the custom facet I created using booleans, I used this piece of GREL to facet out any 856 |3 data that started with a volume label and didn't have a semi-colon:
and(value.startsWith("v"), not(value.contains(";")))
Friday, August 4, 2017
Two recipes for extracting the last n words in a string
Method 1: rpartition
Again, I'm going to post the recipe up here, and go into depth below. If you want the last <n> words in any sentence, you can do a transform with:
rpartition(value, /(\s\S+){<n>}$/)[1]
Be sure that all your data is more than <n> words. If you have sentences that are exactly n words, you'll get a null. You can either custom facet out that data with a :
length(value.split(" ")) ><n>
(what the length GREL does is described in this post.)
or use an if function:
if (length(value.split(" ")) ><n>, rpartition(value, /(\s\S+){<n>}$/)[1], value)
Method 2: Array arithmetic with split
Since you can access any element in split() by using the expression split()[<index>], you can use length(value.split(" ")) to calculate the indexes you need.
To get the last <n> words in any sentence, do a transform with:
value.split(" ")[length(value.split(" "))-<n>] + " " +
value.split(" ")[length(value.split(" "))-<n-1>] + " " +
value.split(" ")[length(value.split(" "))-<n-2>] + " " +
value.split(" ")[length(value.split(" "))-<n-3>] +
etc. until <n-whatever> = 1
ex. If I want the last 4 words in any sentence, my transform GREL would be:
value.split(" ")[length(value.split(" "))-4] + " " +
value.split(" ")[length(value.split(" "))-3] + " " +
value.split(" ")[length(value.split(" "))-2] + " " +
value.split(" ")[length(value.split(" "))-1]
Again, you will get unexpected results if your sentence is less than n words because negative indexes will wrap around. Either facet the short sentences away or use an if function:
if (length(value.split(" ")) ><n>, value.split(" ")[length(value.split(" "))-<n>] + " " + value.split(" ")[length(value.split(" "))-<n-1>] + " " + value.split(" ")[length(value.split(" "))-<n-2>] + " " + value.split(" ")[length(value.split(" "))-<n-3>] + <etc.>, value)
Subscribe to:
Posts (Atom)