More detail will be posted later. I just wanted to note this down.
We needed to extract our course reserves in Millennium into .csv format and the check digit for the item records associated with the instructors was cut off. To further complicate matters, one of our classes had about 106 associated items.
In order to calculate the check digit, you had to do the following calculation:
for item record i1234567, you had to multiply the 7 by 2, the 6 by 3, the 5 by 4, the 4 by 5, the 3 by 6, the 2 by 7, and the 1 by 8. Then, you had to add all those values together, divide by 11, and the remainder was the check digit. Anything that was remainder 10 became check digit x. So, for this item record, the summation is 112. Divide that by 11, and the remainder is 2 - so the full item record number is i12345672.
1. First, I changed the , delimiter right before the item record numbers to } in Notepad++. That way, when I imported to Open Refine, item records i3070797,i3054061,i3054062,i3054064,i3070931,,,,,,,,,,,,,
would all be in the same cell.
2. I split the column of item records into multi-valued cells using the , as a delimiter. My column was named "Column2" for this example.
3. I used add column based on this column and created column "remainder" with this GREL: value.replace ("i","")
This is so I could do the calculation for the check digit in a separate column to make it easier to concatenate later.
3. To do the multiplication and summation calculation, I did a transform on the remainder column and input this GREL:
sum(forEachIndex(reverse(splitByLengths(value,1,1,1,1,1,1,1)),i,v, (i+2)*toNumber(v)))
4. Unfortunately, this inserted a lot of zeros into the fields I wanted to leave blank, so I did another transform on remainder and did this to blank out the zeros: if(value == 0, "", value)
(You could probably just facet on the 0 and blank it out, too). This step has to be done, otherwise the calculation of the remainder will fill in the cells with the zeros with unwanted values.
5. Do another transform on column remainder to calculate the remainder:
mod(value,11)
6. Now concatenate Column2 and remainder together (can be either a transform or a new column):
if(isBlank(value), "",if (cells.remainder.value < 10, value + cells.remainder.value, value + "x"))
(Leaving out the check for isBlank gave me funky values again.)
7. Now remove any extra columns and join multi-valued cells on the concatenated column.
Showing posts with label recipes. Show all posts
Showing posts with label recipes. Show all posts
Thursday, April 12, 2018
Friday, August 18, 2017
Recipe and walkthrough: counting up repeats of a word in a sentence
How do you count up the occurrences of <word> in a sentence? (or, in this case, find how many times "Nintendo" is in a 538?
sum(forEach(value.split(" "), temp, if(temp.contains("Nintendo"), 1, 0)))
Explanation:
Thursday, August 17, 2017
Recipe: Text filtering with regular expressions
An alternative to writing a custom facet, especially if you want to filter based on a single word, is to use Open Refine's text filtering. It has regex capability, which is extremely useful.
For example, I have a file of videogame MARC records. The platforms under system requirements vary in verbiage and spelling. If I wanted to isolate out two platforms, such as all Xbox, Playstation, and Nintendo games, I could just use the text filtering function to find them instead of building a custom facet.
Caveats with the text filtering function - if you have a large file, it may hang. My file unfortunately came out to be about 69,000 rows, which Open Refine didn't like at all when I tried a text filter. I stopped the hanging by switching the view to 10 rows at a time and faceting on the 538 first.
So, to activate the text filter, all I have to do is pull down the menu on the Contents column and select "Text Filter"

A box will pop up in the left hand pane. All I have to do is enter my regular expression for finding all the Xbox and Playstation games: (.*[Nn]intendo.*|.*[Xx]box.*|.*[Pp]laystation.*), check the "regular expressions" box underneath where I entered my regex, and I'm good to go:
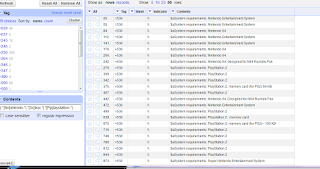
For example, I have a file of videogame MARC records. The platforms under system requirements vary in verbiage and spelling. If I wanted to isolate out two platforms, such as all Xbox, Playstation, and Nintendo games, I could just use the text filtering function to find them instead of building a custom facet.
Caveats with the text filtering function - if you have a large file, it may hang. My file unfortunately came out to be about 69,000 rows, which Open Refine didn't like at all when I tried a text filter. I stopped the hanging by switching the view to 10 rows at a time and faceting on the 538 first.
So, to activate the text filter, all I have to do is pull down the menu on the Contents column and select "Text Filter"

A box will pop up in the left hand pane. All I have to do is enter my regular expression for finding all the Xbox and Playstation games: (.*[Nn]intendo.*|.*[Xx]box.*|.*[Pp]laystation.*), check the "regular expressions" box underneath where I entered my regex, and I'm good to go:

Friday, August 4, 2017
Two recipes for extracting the last n words in a string
Method 1: rpartition
Again, I'm going to post the recipe up here, and go into depth below. If you want the last <n> words in any sentence, you can do a transform with:
rpartition(value, /(\s\S+){<n>}$/)[1]
Be sure that all your data is more than <n> words. If you have sentences that are exactly n words, you'll get a null. You can either custom facet out that data with a :
length(value.split(" ")) ><n>
(what the length GREL does is described in this post.)
or use an if function:
if (length(value.split(" ")) ><n>, rpartition(value, /(\s\S+){<n>}$/)[1], value)
Method 2: Array arithmetic with split
Since you can access any element in split() by using the expression split()[<index>], you can use length(value.split(" ")) to calculate the indexes you need.
To get the last <n> words in any sentence, do a transform with:
value.split(" ")[length(value.split(" "))-<n>] + " " +
value.split(" ")[length(value.split(" "))-<n-1>] + " " +
value.split(" ")[length(value.split(" "))-<n-2>] + " " +
value.split(" ")[length(value.split(" "))-<n-3>] +
etc. until <n-whatever> = 1
ex. If I want the last 4 words in any sentence, my transform GREL would be:
value.split(" ")[length(value.split(" "))-4] + " " +
value.split(" ")[length(value.split(" "))-3] + " " +
value.split(" ")[length(value.split(" "))-2] + " " +
value.split(" ")[length(value.split(" "))-1]
Again, you will get unexpected results if your sentence is less than n words because negative indexes will wrap around. Either facet the short sentences away or use an if function:
if (length(value.split(" ")) ><n>, value.split(" ")[length(value.split(" "))-<n>] + " " + value.split(" ")[length(value.split(" "))-<n-1>] + " " + value.split(" ")[length(value.split(" "))-<n-2>] + " " + value.split(" ")[length(value.split(" "))-<n-3>] + <etc.>, value)
Monday, July 31, 2017
How to calculate the number of words in a sentence and how to use that in facets/the if function
I had a set of data where I needed to only process sentences that were more than a certain number of words. Fortunately, doing so is relatively easy.
First of all, the words in a sentence can be split up into an array using value.split(" ").
Secondly, the length() function in Open Refine returns the length, or total number of elements in an array. Since each element is a word, put these two together and the number of words will be calculated:
First of all, the words in a sentence can be split up into an array using value.split(" ").
Secondly, the length() function in Open Refine returns the length, or total number of elements in an array. Since each element is a word, put these two together and the number of words will be calculated:
Using splitByCharType to extract years of coverage in an 856 field
GREL's splitByCharType() is actually quite a useful function. It takes a string, splits it up, and then groups consecutive like characters together in an array. Some of the more common like characters are all lowercase letters, all uppercase letters, all numbers, and all spaces. Special characters and punctuation are only grouped together with the exact same character (e.g. $$ would be grouped together, but $! would not.)
For example, for the string: $a300 pages ;$c20 cm, it'll fill the array this way:
Index Element
0 $
1 a
2 300
3 <space>
4 pages
5 <space>
6 ;
7 $
8 c
9 20
10 <space>
11 cm
For example, for the string: $a300 pages ;$c20 cm, it'll fill the array this way:
Index Element
0 $
1 a
2 300
3 <space>
4 pages
5 <space>
6 ;
7 $
8 c
9 20
10 <space>
11 cm
Friday, July 28, 2017
Using the Marcedit capturing group Find/Replace in Open Refine, pt.2 : putting it into an if function.
This is a continuation from this post about how to mimic Marcedit capturing group Find/Replace in Open Refine.
The one problem with mimicking the Marcedit Find/Replace is that it will wipe out the data you don't want to alter unless you facet it out first. This is kind of cumbersome and still doesn't have the convenience of Marcedit's Find/Replace.
However, the if function takes care of that problem. I'm going to post the recipe here at the top and then go into detail further down. So, for your capturing group find of value.match(/<capturing group regex>/), do a transform cells, and drop it into this statement:
if(isNotNull(value.match(/<your find>/)), <your replace>, value)
The one problem with mimicking the Marcedit Find/Replace is that it will wipe out the data you don't want to alter unless you facet it out first. This is kind of cumbersome and still doesn't have the convenience of Marcedit's Find/Replace.
However, the if function takes care of that problem. I'm going to post the recipe here at the top and then go into detail further down. So, for your capturing group find of value.match(/<capturing group regex>/), do a transform cells, and drop it into this statement:
if(isNotNull(value.match(/<your find>/)), <your replace>, value)
Thursday, July 27, 2017
How to do a Marcedit Find/Replace with capturing groups in Open Refine
One of the things that's really frustrated me with Open Refine is that there didn't seem to be a way to mimic the capturing group rearranging from the Find/Replace function in Marcedit.
For example, in this import of Marcedit records, some of the subfield a's have an indicator in front of them:
In Marcedit, I'd normally do this:
But I couldn't figure out how to do the equivalent in Open Refine. value.match seemed like a contender, but I couldn't figure out how to access the array elements. I finally figured it out today --
For example, in this import of Marcedit records, some of the subfield a's have an indicator in front of them:
 |
| Click on image to enlarge |
In Marcedit, I'd normally do this:
 | ||||||
| click on image to enlarge |
But I couldn't figure out how to do the equivalent in Open Refine. value.match seemed like a contender, but I couldn't figure out how to access the array elements. I finally figured it out today --
Friday, July 21, 2017
How to remove duplicate rows
Here's a pointer to a page that gives detailed instructions on how to remove duplicate data: http://kb.refinepro.com/2011/08/remove-duplicate.html
Tuesday, July 18, 2017
Using facets to debug search differences for large files
I was using Millennium's Create List search, but then I needed to tweak it a bit. The problem I had is that the file was rather huge (15K worth of records) and it was going to be a bear to figure out which records had fallen out of the old search and which new records had been picked up.
Usually, I would dump both lists of record numbers into Excel, highlight the duplicate values, and scroll through, but that wasn't feasible for quickly checking 15K records.
Instead, I was able to use Open Refine's faceting ability to help me filter through the data. I dumped the record numbers from the old search into one column in Excel (labeled "Column 1"), dumped the record numbers from the new search into a second column (labeled "Column 2"), saved, and then sent the sheet over to Open Refine.
Then I clicked on "false" in the facet to see what wasn't matching. Note that you have to use the object cells and not cell. I should also note that this expression isn't too useful if the two columns are wildly out of sync. It's mostly useful for needle in a haystack situations.
Usually, I would dump both lists of record numbers into Excel, highlight the duplicate values, and scroll through, but that wasn't feasible for quickly checking 15K records.
Instead, I was able to use Open Refine's faceting ability to help me filter through the data. I dumped the record numbers from the old search into one column in Excel (labeled "Column 1"), dumped the record numbers from the new search into a second column (labeled "Column 2"), saved, and then sent the sheet over to Open Refine.
I hit the drop down menu on any column and chose Facet->Custom Text Facet.
Then I entered this GREL:
cells["Column 1"].value == cells["Column 2"].value


If structure cheat sheet
Updated 8/24/17
If structure cheat sheet
If structure cheat sheet
<operation> can be any function – reprinting a cell
value, concatenating cells values, any string processing function listed in the
wiki, and even a foreach, with, or another if function.
Do <operation> only if test
condition is false
|
if (test condition, value,
<operation>)
|
Do <operation> only if test
condition is true
|
if (test condition,
<operation>, value)
|
Do <operation1> if test
condition is true, otherwise do <operation 2>
|
if (test condition, <operation
1>, <operation 2>)
|
Do a Marcedit Find/Replace on string1 string2 string3 to transform
it into string2; string3; string1
|
if (isNotNull(value.match(/(regex for string1)(regex for string2)(regex
for string3)/)), value.match(/(regex
for string1)(regex for string2)(regex for string3)/)[1] + “;” + value.match(/(regex for string1)(regex for string2)(regex
for string3)/)[2] + “;” + value.match(/(regex for string1)(regex for string2)(regex for string3)/)[0],
value)
|
Test Condition Cheat Sheet
Example data to be used is
auto
autos
auto mechanics
automechanics
auto mechanics and aviation
planes
trains
automobiles
aviation
aviation and automechanics
auto
autos
auto mechanics
automechanics
auto mechanics and aviation
planes
trains
automobiles
aviation
aviation and automechanics
NOTE : Test
conditions can also be used for custom text faceting
Test Condition
|
Code
|
String must exactly match auto
|
value == “auto”
|
String can be auto, autos, auto mechanics, automechanics, or auto mechanics and aviation
|
value.contains("auto")
|
String can be auto mechanics, automechanics, auto mechanics, or auto mechanics and aviation.
|
isNotNull(value.match(/(.*auto.*mechanics.*)/))
|
String can be auto, autos, planes, trains, or automobiles.
|
isNull(value.match(/(.*auto.*mechanics.*)/))
|
| String must match auto, autos, or planes. | or(isNotNull(value.match(/(^auto[s]/))), value == "planes") |
String must start with some variation of auto.
|
value.startsWith("auto")
|
Find all of the variations of auto mechanics and aviation
|
and(isNotNull(value.match(/(.*auto\s*mechanics.*)/)), value.contains("aviation"))
|
| All strings that begin with "a" |
value.startsWith("a")
|
All strings that end with "s"
|
value.endsWith("s")
|
String must be less than 4 words
|
length (split(value, “ “)) < 4
|
String must contain any substring with variable spacing of “auto mechanics”
and must be less than 4 words
|
and(isNotNull(value.match(/.*auto.*mechanics.*/)),
length(split(value, " ")) < 4)
|
Cell is completely blank
|
isBlank(value)
|
Cell is not blank
|
isNonBlank(value)
|
Test conditions for dates
Test string is a single range of years, such as 1938-1968.
No spaces surrounding the hyphen.
First year must be greater than 1938
|
toNumber(substring(value, 0,4)) > 1938
|
First year must equal 1938
|
toNumber(substring(value, 0,4)) == 1938
|
First year must be less than 1938
|
toNumber(substring(value, 0,4)) < 1938
|
Second year must be less than 1968
|
toNumber(substring(value,5,9)) < 1968
|
Second year must be equal 1968
|
toNumber(substring(value,5,9)) == 1968
|
Second year must be less greater than 1968
|
toNumber(substring(value,5,9)) > 1968
|
Second year is greater than the first
|
toNumber(substring(value,5,9)) > toNumber(substring(value,0,4))
|
Subscribe to:
Posts (Atom)