Recipe:
Given this truncated sample data:

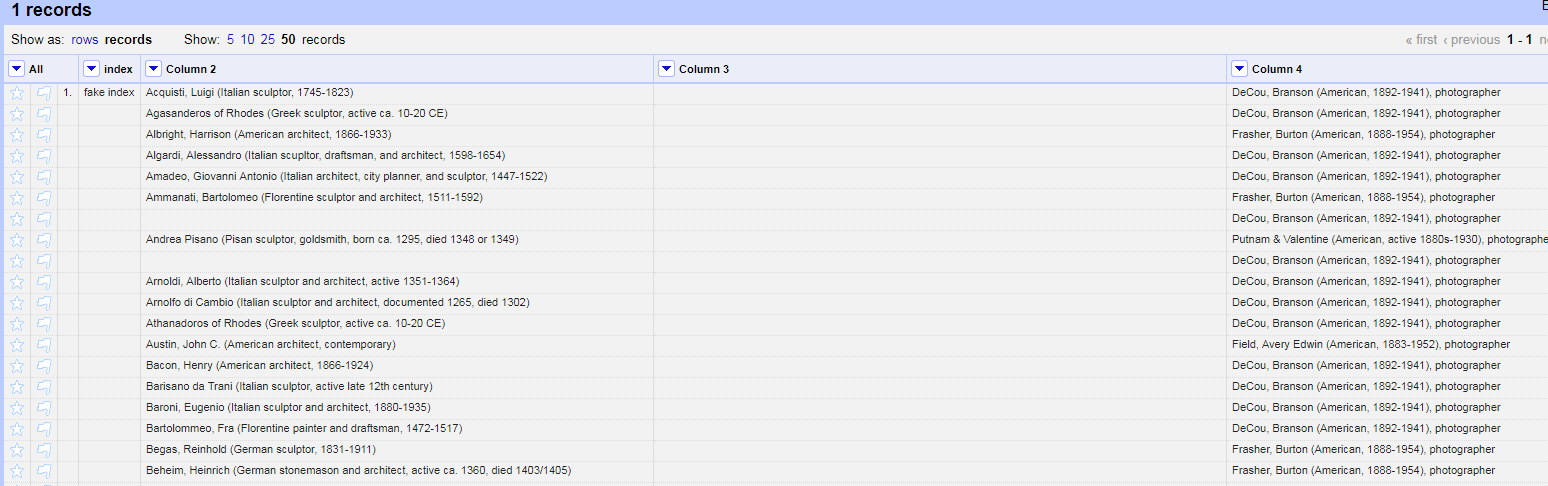
Assuming that there are more entries that aren't being shown, if I only want to join the two subject headings in Column 4 for Ammanati, Bartolomeo:
- Make sure you're in the row view before you proceed
- Add column based on any column, with whatever name (I'm calling it index), and "" in the Expression box.
- Edit the very first cell in index, put in a placeholder value. (NOTE: put in one placeholder value only, doing two won't work.)
- Move index to the first column position.
- Switch to record view. (Note : this appears to be optional in Open Refine 2.9, but you may need to do it for older versions.)
- Because I found it hard to read recipes with other people's column names, I am referring to Column 2, as the <test column>. (Since this is the column you use as the test condition for the if statement). Column 4 will be referred to as the <edit column>, to indicate which column I want to edit.
- Transform on <edit column> : if(cells["<test column>"].value.contains("Ammanati"), row.record.cells["<edit column>"].value[rowIndex] + ";" + row.record.cells["<edit column>"].value[rowIndex+1], value)
- Transform on <test column> and create a placeholder row: if(row.record.cells["<test column>"].value[rowIndex-1].contains("Ammanati"), "place", value)
- Switch to row view.
- Custom text facet on <test column>: value.contains("place"), select true
- Star the placeholder rows.
- Remove the custom facet and facet by star
- All->edit rows->remove matching rows.
- Remove the index column.
Long, detailed explanation:
Joining only selected cells has something that has eluded me for a while. However, I was trying to figure out how to shift cells upward in Open Refine, and I found a recipe that basically tricks Open Refine and causes all its rows to be inserted into the row.record.cells.<column>.value array.
Once the rows are in the array, the elements can be accessed using the rowIndex variable.
The first thing to do is to get the rows into the array. This is done by basically making the entire spreadsheet one record.
1. First, make sure you're in the row view before you start.
2. Then, do an add column on wherever, and add a blank column:


3. Now, put a placeholder value in the first cell in your blank column: (only do one, otherwise the trick won't work)

4. Move the column to the beginning of the spreadsheet using edit column:

5. Switch to record view. You should only see one row numbered. If not, try filling down and then blanking down on the first column.
6. In row view, each row is its own separate object. In record view, every numbered line becomes an object and all of the rows between that and the next numbered line are considered part of the object.
Normally, this doesn't make a difference when you have every row filled. However, when you have only one row in the first column, that forces the entire spreadsheet to become a single object associated with a single record.
Row view:

This means that each column is an accessible array. Here's the record view:
(Note, I haven't confirmed this, but it looks like in Open Refine 2.9, all that you need to do to force this is to create a column with only one value and move it to the beginning.)

It's a little hard to see, but basically, Column 4 has now been placed in an array, called the row.record.cells["Column 4"].value array, and it looks like this:
Index Element
0 DeCou, Branson (American, 1892-1941), photographer
1 DeCou, Branson (American, 1892-1941), photographer
2 Frasher, Burton (American, 1888-1954), photographer
3 DeCou, Branson (American, 1892-1941), photographer
4 DeCou, Branson (American, 1892-1941), photographer
5 Frasher, Burton (American, 1888-1954), photographer
etc...
So how do you access the elements in the row.record.cells["Column 4"].value array? If you use flat numbers, you'll only get that element, like so:

That doesn't help when you don't know the exact element number for your data, or if you have multiple entries to process.
Fortunately, there are two things that can help you. One is the rowIndex variable. row.index is generated when you first create the Open Refine project - each row in the spreadsheet is numbered, starting at zero, and that number is stored in the row.index field. Open Refine mapped rowIndex to row.index, for ease of typing, so I'm using that name.
What rowIndex looks like:

Also, when the array was created, Open Refine retrieved every rowIndex for that row, and mapped that to the element indexes in the row.record.cells["Column 4"].value array. So, rowIndex 0 is index 0 in the array, rowIndex 1 is index 1 in the array, etc.
The second thing that can help you access the elements in the row.record.cells["Column 4"].value array is the fact that when you do a transform or an add column with a variable element label, what Open Refine will do behind the scenes is to automatically apply your GREL code to every single element in the array, sequentially. (a.k.a. looping)
What exactly do I mean?
Let's step through what Open Refine does when you type in
row.record.cells["Column 4"].value[rowIndex]
What any type of programming language does when it sees a variable, is that it looks up what the value is for that variable and drops it in before it evaluates the expression. So, the sequence is - look up, drop in, evaluate. The look up and drop in phases are all basically done in Open Refine's head, so you won't really see it doing those intermediate steps.
For ease of looking up, here's the array again:
Index Element
0 DeCou, Branson (American, 1892-1941), photographer
1 DeCou, Branson (American, 1892-1941), photographer
2 Frasher, Burton (American, 1888-1954), photographer
3 DeCou, Branson (American, 1892-1941), photographer
4 DeCou, Branson (American, 1892-1941), photographer
5 Frasher, Burton (American, 1888-1954), photographer
etc...
And here's the row and rowIndex chart
Row rowIndex
1 0
2 1
3 2
4 3
5 4
6 5
Starting at row 1:
Look up - Open Refine looks up rowIndex for row 1.As you can see from the picture above, rowIndex for row 1 is 0, so Open Refine retrieves it and holds on to it in its head.
Drop in - Open Refine now drops in the 0 into where it sees rowIndex in the expression. So in its mind
row.record.cells["Column 4"].value[0]
is the current expression.
Evaluate - row.record.cells["Column 4"].value[0] is a command to output element 0 of the array. Open Refine outputs DeCou, Branson (American, 1892-1941), photographer to row 1.
Row 2:
Look up - Open Refine looks up rowIndex for row 2, which is 1, and mentally stashes it.
Drop in - Open Refine drops in rowIndex for row 2 now. So, now it thinks
row.record.cells["Column 4"].value[1]
Evaluate - row.record.cells["Column 4"].value[1] is a command to output element 1 of the array. Open Refine outputs DeCou, Branson (American, 1892-1941), photographer to row 2.
Row 3:
Look up - Open Refine looks up rowIndex for row 3, which is 2, and mentally stashes it.
Drop in - Open Refine drops in rowIndex for row 2 now. So, now it thinks
row.record.cells["Column 4"].value[2]
Evaluate - row.record.cells["Column 4"].value[2] is a command to output element 1 of the array. Open Refine outputs Frasher, Burton (American, 1888-1954), photographer to row 3.
Picture:

So, how does this apply to joining two sequential cells in a column? Well, it's basically a math/programming trick. Remember x and x+1 from algebra, where if x =3, x+1 =4? You're doing the same thing here with array indexes.
Let's step through Open Refine again, but this time with
row.record.cells["Column 4"].value[rowIndex+1]
Starting at row 1:
Look up - Open Refine looks up rowIndex for row 1.As you can see from the picture above, rowIndex for row 1 is 0, so Open Refine retrieves it and holds on to it in its head.
Drop in - Open Refine now drops in the 0 into where it sees rowIndex in the expression. So in its mind
row.record.cells["Column 4"].value[0+1]
is the current expression.
Evaluate - Here's where things are a little different. The "+1" is considered a sub-command for any programming language. Sub-commands are resolved first before the main command is resolved.
So, first, the addition is performed - 0+1 = 1.
The expression now becomes row.record.cells["Column 4"].value[1]
Now the main command is evaluated. Open Refine looks up the element indexed by row.record.cells["Column 4"].value[1] and
outputs DeCou, Branson (American, 1892-1941), photographer to row 1.
Row 2:
Look up - Open Refine looks up rowIndex for row 2. rowIndex for row 2 is 1, so Open Refine retrieves it and holds on to it in its head.
Drop in - Open Refine now drops in the 1 into where it sees rowIndex in the expression. So in its mind
row.record.cells["Column 4"].value[1+1]
is the current expression.
Evaluate - Again, sub-commands are resolved before the main command.
So, first, the addition is performed - 1+1 = 2.
And now the expression is row.record.cells["Column 4"].value[2]
Now the main command is evaluated. Open Refine looks up the element indexed by row.record.cells["Column 4"].value[2] and
outputs Frasher, Burton (American, 1888-1954), photographer to row 2.
Row 3:
Look up - Open Refine looks up rowIndex for row 3. rowIndex for row 3 is 2, so Open Refine retrieves it and holds on to it in its head.
Drop in - Open Refine now drops in the 2 into where it sees rowIndex in the expression. So in its mind
row.record.cells["Column 4"].value[2+1]
is the current expression.
Evaluate - Again, sub-commands are resolved before the main command.
So, first, the addition is performed - 2+1 = 3.
And now the expression is row.record.cells["Column 4"].value[3]
Now the main command is evaluated. Open Refine looks up the element indexed by row.record.cells["Column 4"].value[3] and
outputs DeCou, Branson (American, 1892-1941), photographer to row 3.
Look up - Open Refine looks up rowIndex for row 4. rowIndex for row 4 is 3, so Open Refine retrieves it and holds on to it in its head.
Drop in - Open Refine now drops in the 3 into where it sees rowIndex in the expression. So in its mind
row.record.cells["Column 4"].value[3+1]
is the current expression.
Evaluate - Again, sub-commands are resolved before the main command.
So, first, the addition is performed - 3+1 = 4.
And now the expression is row.record.cells["Column 4"].value[4]
Now the main command is evaluated. Open Refine looks up the element indexed by row.record.cells["Column 4"].value[4] and
outputs DeCou, Branson (American, 1892-1941), photographer to row 4.

If this is still confusing, make a spreadsheet with these values:
row contents
1 first
2 second
3 third
4 fourth
5 fifth
6 sixth
Put in the placeholder column, and then play around with seeing what pops up in the preview window with these expressions:
row.record.cells["Column 4"].value[rowIndex]
row.record.cells["Column 4"].value[rowIndex+1]
row.record.cells["Column 4"].value[rowIndex+2]
row.record.cells["Column 4"].value[rowIndex+3]
row.record.cells["Column 4"].value[rowIndex-1]
Now that you're more familiar with how the array arithmetic works, here's what would happen if I entered:
row.record.cells["Column 4"].value[rowIndex] + "; " + row.record.cells["Column 4"].value[rowIndex+1]
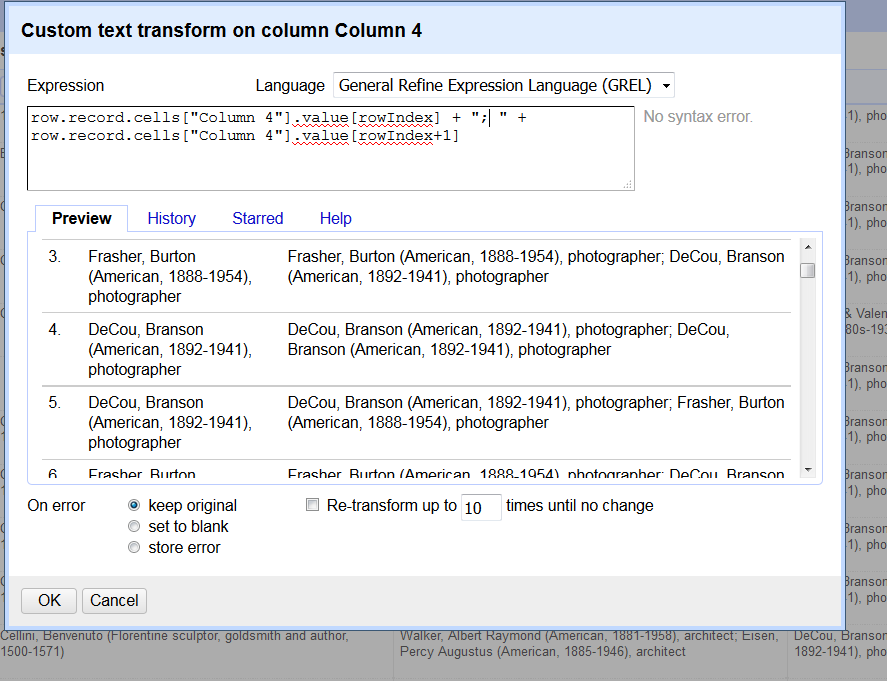
Anyway, so now that I know how to do the concatenation, all I have to do is set up my if statement for the transform. That's not hard, all I have to do is make it a value.contains() from Column 2 to look for Ammanati. The concatenation goes in the "execute if true" section, and just value goes into the "execute if false" section.
Or:
if(cells["Column 2"].value.contains("Ammanati"), row.record.cells["Column 4"].value[rowIndex] + ";" + row.record.cells["Column 4"].value[rowIndex+1], value)


7. Now that I've done the concatenation, just to keep the formatting, I'm going to get rid of the row below. (This is optional - if you don't care about the formatting, you could just clear the cell with the extra data.)
Usually, when you want to get rid of rows, you figure out some way to star the rows and then you delete them. The easiest way to do this is to insert a placeholder on the row I want to remove.
The problem is that the row I want to remove is a blank row and there are several other blank rows on the spreadsheet. In addition, null rows appear to not have been pushed onto the array.
So, since I can't look for blank rows, what I can do is look for Ammanati again. However, I can only write the placeholder on the row currently being accessed, so if I try to write the placeholder when I see Ammanati, I'll nuke it.
What I can do instead is to check the row above the row being accessed using array arithmetic again. If rowIndex+1 will get the row below the row being accessed, rowIndex-1 will get the row above the row being accessed.
E.g.
row.record.cells["Column 2"].value[rowIndex-1] will check the line above:

By the way, row.record.cells["Column 2"].value[rowIndex-1] won't be null for row 1 because index -1 in an array wraps around and indexes the last element.
Now that I know how to check the row above, all I have to do is drop this into my if statement. In pseudo-code:
if
row above contains "Ammanati"
put placeholder value "place" in the cell if true
do nothing if false
or:
if(row.record.cells["Column 2"].value[rowIndex-1].contains("Ammanati"), "place", value)

8. Now that we've got our placeholder, switch back to row view.
9. Custom text facet on Column 2:

10. Star the rows to be removed:


11. Close the facet. Now, facet by star:

12. Select the true facet. And now, delete the rows:

13. The last thing to do is to delete the index column.
No comments:
Post a Comment