The value.match documentation on the Open Refine github wiki is a bit daunting, so I'm going to try to break it down in this post.
Some programming speak first: GREL functions usually yield some sort of data after they're done doing their thing. That data is called a return value. So, that's what I'm referring to whenever I make statements like, "match returns <whatever>".
Anyway, the biggest hurdle to my understanding was figuring out how match and regular expressions worked together. Here's what I've determined:
Unlike Marcedit, you have to account for the whole line if you're using regex in match. - In Marcedit and any other regex engine, if you just want look for lines with subfield e, you could just do \$e.
- You can't do that in match. It looks at the line as a whole, so unless the line just consists of subfield e, you'll have to write your match expression as value.match(/.*\$e.*/), or else you'll get a null return value.
Don't forget that if you're using regex, to put / / around your regex expression.
This is easy to forget because Marcedit doesn't require it.
Unless you use capturing groups in match, the data you're matching on is dumped.
By default, Marcedit would put .*\$e.* into $1. GREL does it differently. When it gets a valid match on regex, it does the following actions:
This is easy to forget because Marcedit doesn't require it.
Unless you use capturing groups in match, the data you're matching on is dumped.
By default, Marcedit would put .*\$e.* into $1. GREL does it differently. When it gets a valid match on regex, it does the following actions:
- Creates an empty array (Arrays are detailed here if you're unfamiliar with them.)
- Pushes the strings contained in each capturing group into the appropriate data element.
- However, this means that if no capturing groups were used when writing the match statement, the data basically gets dumped.
- So, if I try to use GREL expression value.match(/.*\$e.*/), it returns an empty array (you'll see it as [ ])
Why should I care about empty arrays?
You can use them for boolean statements. More on that later.
Only the data defined in a capturing group is inserted into the match array.
The match function won't insert data into its array until it's put into a capturing group. For example,
say I had a bunch of 300 fields with an erroneous $e notation that I need to remove. Unfortunately, the data before the subfield e and the data after the subfield e wildly varies and is impossible to facet.
You can remove the subfield by doing a value.match and then manipulating the array elements. The goal is to insert all of the data before subfield e into one array element, subfield e in the second, and everything after into the third element.
However, if I wrote my expression as:
say I had a bunch of 300 fields with an erroneous $e notation that I need to remove. Unfortunately, the data before the subfield e and the data after the subfield e wildly varies and is impossible to facet.
You can remove the subfield by doing a value.match and then manipulating the array elements. The goal is to insert all of the data before subfield e into one array element, subfield e in the second, and everything after into the third element.
However, if I wrote my expression as:
value.match(/.*(\$e).*/)
Instead of having the data look like this:
["<everything before subfield e>", "$e", "<everything after subfield e>"]
my array would instead be:
["$e"]
If, instead, I wrote my expression as:
value.match(/.*(\$e.*)/)
value.match(/.*(\$e.*)/)
That still wouldn't be correct, because this would be in the array:
["$e<everything after subfield e>"]
Instead, the correct expression is:
value.match(/(.*)(\$e)(.*)/)
In the cases where you want to dump certain bits of data, you could take advantage of the fact that match doesn't insert a non-captured group of data into the array, but I wouldn't do that until you're very comfortable with how match works. My suggestion is to proceed as you would in a find/replace in Marcedit - break the string apart into capturing groups, and then concatenate together the groups you want to keep (along with whatever other data you want to add).
You can access the elements in the match array with the syntax value.match(<whatever reg ex you wrote>)[index number] and work with them just like any other string.
Anytime you have a GREL function that generates an array, you can access the individual elements of the array by sticking the index number of the array on the end of your original GREL function.
i.e. value.match(/(.*)(\$e)(.*)/)
generates the array:
["<everything before subfield e>", "$e", "<everything after subfield e>"]
To access each element, you would use these expressions:
value.match(/(.*)(\$e)(.*)/)[0] = will output <everything before subfield e> to the spreadsheet
value.match(/(.*)(\$e)(.*)/)[1] = will output $e to the spreadsheet
value.match(/(.*)(\$e)(.*)/)[2] = will output <everything after subfield e> to the spreadsheet
You can manipulate an array element like any other string, just drop in value.match(/<reg ex>/)[index] where you would normally use value.
So, to complete our task of editing out the subfield e, the transformation recipe you would use is:
value.match(/(.*)(\$e)(.*)/)[0] +
value.match(/(.*)(\$e)(.*)/)[2]
The elements in match are very much like $1, $2, $3, etc. in Marcedit. The only difference is the index starts at 0 instead of one, and instead of a $ you get to write out the whole match expression.
value.match(/(.*)(\$e)(.*)/)
In the cases where you want to dump certain bits of data, you could take advantage of the fact that match doesn't insert a non-captured group of data into the array, but I wouldn't do that until you're very comfortable with how match works. My suggestion is to proceed as you would in a find/replace in Marcedit - break the string apart into capturing groups, and then concatenate together the groups you want to keep (along with whatever other data you want to add).
You can access the elements in the match array with the syntax value.match(<whatever reg ex you wrote>)[index number] and work with them just like any other string.
Anytime you have a GREL function that generates an array, you can access the individual elements of the array by sticking the index number of the array on the end of your original GREL function.
i.e. value.match(/(.*)(\$e)(.*)/)
generates the array:
["<everything before subfield e>", "$e", "<everything after subfield e>"]
To access each element, you would use these expressions:
value.match(/(.*)(\$e)(.*)/)[0] = will output <everything before subfield e> to the spreadsheet
value.match(/(.*)(\$e)(.*)/)[1] = will output $e to the spreadsheet
value.match(/(.*)(\$e)(.*)/)[2] = will output <everything after subfield e> to the spreadsheet
You can manipulate an array element like any other string, just drop in value.match(/<reg ex>/)[index] where you would normally use value.
So, to complete our task of editing out the subfield e, the transformation recipe you would use is:
value.match(/(.*)(\$e)(.*)/)[0] +
value.match(/(.*)(\$e)(.*)/)[2]
The elements in match are very much like $1, $2, $3, etc. in Marcedit. The only difference is the index starts at 0 instead of one, and instead of a $ you get to write out the whole match expression.
How in heck do you use match for a boolean statement?
The frustrating thing about match is that it doesn't return a true/false value. This particularly inhibits true/false faceting or using the if function. (This is quite different from Perl and C, where a string match expression will return a boolean.)
The big problem is that most selective editing work needs to use match and regex to select the data because of the high variability factor. Unfortunately, match only returns null, an empty array ([ ]), or an array.
However, Open Refine actually has a way to transform match into something that will yield a boolean value. And that's the isNull and isNotNull functions.
isNull(<GREL expression>) = returns true if <GREL expression> returns Null, false otherwise.
isNotNull(<GREL expression>) = returns true if <GREL expression> does not return Null, false otherwise.
If you drop in value.match into the <GREL expression> part, you have isNotNull(value.match(/<reg ex for matching the string you want>/)). Boom, you have a boolean.
Okay, now how does this apply to working with data?
 |
| Click to enlarge |
I only want the 300's with ;$e and not any of the others.
The quickest way to isolate would be to build a true/false facet based on value.match. There are two ways to do this.
Method 1: The first way is to construct a regex with capturing groups. So, in this case, since I only want the 300's with ;$e, I would write my regex as value.match(/(.*)(;\$e)(.*)/)
(You could technically write your regex as value.match(/(.*;\$e.*)/), but I want to reinforce the concept of how value.match inserts capturing groups into the array.)
Before I do anything else, I want to check my regex against my data, and make sure only the 300's with ;$e are placed into an array. Everything else should have a "null". So facet->custom text facet, and then I check my regex to make sure it works:
 |
| If you have a match, your string should be in an array, no match is null |
When doing regex, it's also important to make sure you also check the data that shouldn't match up. So, I'm doing a scan of the other 300 fields, one with the correct + $e, and just a generic 300 to make sure they both say "null":
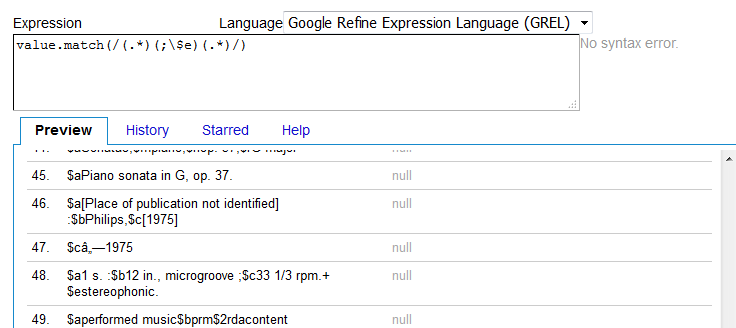

They do, so now I proceed to the next step- cutting and pasting my value.match regex inside isNotNull(). If it's done correctly, the line I want to work on should have "true" and all others should have "false":

Again, spot check the other 300s to make sure that they are "false":


If everything looks good, hit "Ok" and then edit on the "True" facet.
Method 2: Read method 1 before you look at this section.
The second way is to take advantage of the fact than an empty array is technically not counted as a null. So, again, you would use value.match() to build your facet, but this time, you will use the regex value.match(/.*;\$e.*/). Doing so will generate these results:

As you can see, the other lines are "null", but the line with ;$e has the [ ] notation. That's because it matched, but since I didn't use a capturing group, the data wasn't saved in the array. However, look at what happens when I use isNotNull () around the value.match():
 |
| Empty arrays yield a true result |
Which one is better to use? If you are purely faceting, are super comfortable with all of the ins and outs of value.match with regex, this is a fine method to avoid typing lots of parentheses for capturing groups.
If you're still learning value.match, and are more comfortable with Marcedit regex find and replace, I would use Method 1.
No comments:
Post a Comment